
Image by Loren Javier, available via CC BY-ND 2.0
Indexation bloat is when a website has pages within a search engine “index” and can cause issues if not monitored and policed properly.
It is an extremely common SEO problem and affects all websites, ranging from small WordPress blogs to big Hybris and Magento ecommerce websites.
The more serious cases of indexation bloat usually occur on ecommerce websites, as they tend to utilize user-friendly facetted navigations and filter lists, allowing users to quickly identify the products that they want.
I’ve seen examples first hand of simple Demandware and Open Cart websites with only a few hundred products having millions of URLs appear in Google’s index because of the product filters generating URLs.
Why is indexation bloat a problem?
It’s a known fact that when Google and the other search engines crawl your website, they don’t crawl your website in its entirety. Allowing and asking them to crawl unnecessary URLs wastes this resource.
If search engines aren’t regularly crawling your “money” pages and are instead getting stuck down other rabbit holes without picking up on updates, this could impact your organic performance.
Bloat can also lead to duplicate content issues. While internal website content duplication isn’t as serious an issue as external duplication, it could dilute an individual page’s prominence and relevancy for search terms if the page itself as the search engines aren’t sure which URL to rank for the terms.
Identifying index bloat issues
One early indicator of index bloat is the number of pages appearing within search engine results.
It’s important to note here that the number of pages typically identified using the site: operator within Google and Bing search often show different numbers to what you see in Google Search Console and Bing Webmaster Tools — this isn’t something to worry about.
Website monitoring
While there are ways to resolve index bloat, the best way, in my experience, to deal with it is to prevent it from happening at all.
By checking Google Search Console and Bing Webmaster Tools on a monthly basis, specifically at crawl data, you can record what is and isn’t regular behavior for your website.
Abnormal increases, or spikes in the “Pages crawled per day” and “Kilobytes downloaded per day” can be indicators that Google is accessing more URLs than it has been.

Likewise conducting a site: search within Google and Bing will let you see how many URLs they have in the index, and you’ll know roughly how many pages your website has.
How can I fix indexation bloat?
Identifying that you have an index bloat issue is only step one, now you have to establish what is causing the bloat.
These are some of the most common causes of indexation bloat, but it’s also not uncommon to have more than one of these causes.
- Domain URLs being served through both http and https protocols
- Printable versions of pages causing a duplicate URL
- Parameter URLs caused by internal search
- Parameter URLs caused by product filters
- Pagination
- Blog taxonomies
- Session IDs in URLs
- Injection of spam pages following a hack
- Old URLs not redirected properly following a migration
- Trailing slashes at the end of URLs causing duplication
- UTM source
Fixing with meta robots
A page level meta robots tag is my preferred method of dealing with index bloat and is particularly useful if implemented from a server level across multiple pages at once.
Page level meta robots also take precedence over pagination and canonicalization directives, as well as the robots.txt file (unless blocked in the robots.txt file).
These are also effective at removing URLs containing parameters caused by product filters, faceted navigations and internal search functions. Blocking these in the robots.txt file isn’t always best as it can cause some issues between what different Google user agents can see, which can negatively impact paid search campaigns.
Best practice would be to use “noindex,follow” — this way any backlinks pointing to the page will still pass equity onto the domain.
Robots.txt File
Blocking URL parameters in the robots.txt file is both a great preventative and reactive measure, but it isn’t an absolute solution.
All a Robots.txt file does is direct search engines not to crawl a page, but Google can still index the page if the page is being linked to internally or from external sites. If you know where these internal links are, add a rel=”nofollow” to them.
Canonical tags
Self-referencing canonicalization is typically best practice, apart from on bloated URLs. Ecommerce platforms, like Open Cart, can create multiple URLs for the same product and category.
Adding a canonical tag to the headers of the unnecessary product and category URLs pointing to the “main” one will help search engines understand which version of the page should be indexed.
However, the canonical directive is only a directive, and can be ignored by search engines.
Pagination
Pagination issues can arise from blog post and blog category pages, product category pages, internal search results pages; basically any element of a website that has multiple pages.
Because these pages will contain the same meta information, search engines can confuse the relationship between them and could decide it’s duplicate content.
Using rel=”next” and rel=”prev” pagination markup will help the search engines understand the relationship between these pages and, along with configuration in Google Search Console, decide which ones need indexing.
Using Google Search Console’s URL parameter tool
The URL parameter tool can be used to tell Google what specific parameters do to content on a page (i.e. sort, narrow, filter). Like other methods previously mentioned, you need to make sure you’re not accidentally requesting Google to not index URLs that you want in the index, and not to specify a parameters behaviour incorrectly.
Google classifies your parameters into two categories; active and passive. An active parameter is something that impacts content on a page, so a product filter and a passive parameter is something like a session ID or a UTM source.
This should only really be used as a last resort and used correctly in conjunction with other methods, otherwise this could negatively impact the domain’s organic search performance.
Before using this tool, be sure to read Google’s official documentation and guidance.
The URL removal tool
Depending on the authority of your domain, Google could take a while to recognize and filter out the URLs you want removing. After you have implemented something to tell Google not to index the URL again (a page level meta robots tag), you can request that Google removes the URL from index via Google Search Console.
This is only a temporary measure as it will only hide the URL for 90 days from Google search results, but it doesn’t affect Google crawling and indexing the URL.
This is good to use if you don’t want users being able to find certain pages, but each URL has to be submitted individually so this isn’t a great solution if you have severe index bloat.
Index bloat resulting from a hack
Now, obviously if your website has been hacked, index bloat is definitely not going to be a priority concern. But the bloat from a hack can cause issues for the domain.
The below screenshot is of a Swiss (.ch) domain that operates within Europe, weeks after a hack:

The website itself only has around 50 pages, but as you can see Google is currently indexing 112,000.
This means that, among other things, those 50 pages of product and product information pages are now lost among thousands of hacked URLs, so any updates to these pages may take weeks to get noticed – especially if your website doesn’t command a large crawl budget.
Another indicator of this can be a sudden increase in search visibility (for irrelevant terms):
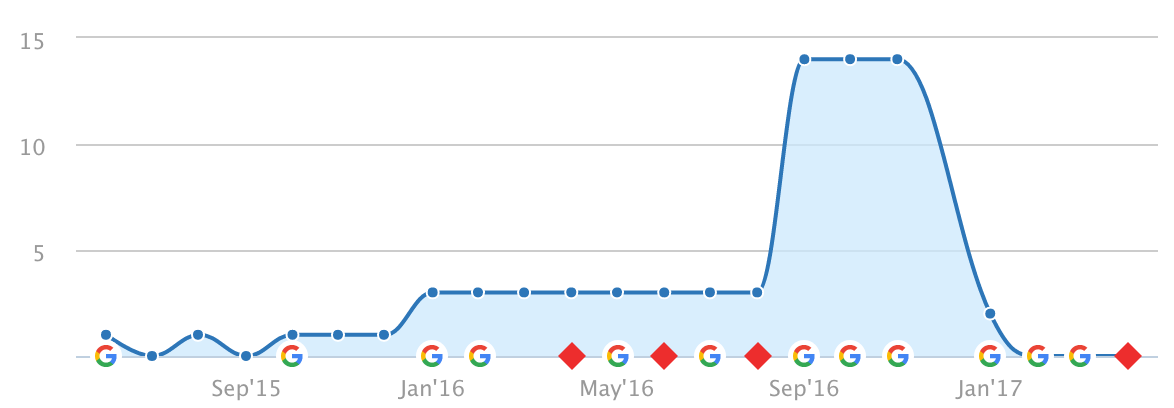
I’ve worked on websites previously where this has been the first indicator. Whilst running a routine monthly check in Google Search Console, a website that dealt in christening gowns had started ranking for “cheap NFL jerseys” and other American sportswear terms.
These visibility spikes are often short-lived, but can destroy the trust between Google and your domain for a long time, so a lot can be said for investing in cyber security beyond https.
Conclusion
Reducing index bloat doesn’t happen overnight, so it’s important to remain patient.
It’s also important to put in place a process or framework, and giving ownership of said process to someone to conduct on a regular basis.
Related reading

A new study commissioned by Microsoft’s Bing and search agency Catalyst may have some light to shed onto why many marketers aren’t realizing the full potential of search.

On its Developers blog, Google stealthily launched some new guidelines for structured data to bring rich results for podcasts to search results. What does it look like, and how can you get your podcasts indexed?

One report by VoiceLabs predicts that voice device growth will quadruple this year. What data can help us to understand the impact of voice search when it isn’t yet a reporting field provided by most publishers? And what are the implications for search marketers?

Over the past 20 years, Google has revolutionized how we source information, how we buy products, and how advertisers sell those products to us. And yet, one fact remains stubbornly true: the shop-front for brands on Google is still the Search Engine Results Page (SERP).
Go to Source
Author: Dan Taylor
For more SEO, PPC & online marketing news visit https://news.scott.services
The post How to identify and fix indexation bloat issues appeared first on Scott.Services Online Marketing News.
source https://news.scott.services/how-to-identify-and-fix-indexation-bloat-issues/
No comments:
Post a Comment