
JavaScript-powered websites are here to stay. As JavaScript in its many frameworks becomes an ever more popular resource for modern websites, SEOs must be able to guarantee their technical implementation is search engine-friendly.
In this article, we will focus on how to optimize JS-websites for Google (although Bing also recommends the same solution, dynamic rendering).
The content of this article includes:
1. JavaScript challenges for SEO
2. Client-side and server-side rendering
3. How Google crawls websites
4. How to detect client-side rendered content
5. The solutions: Hybrid rendering and dynamic rendering
1. JavaScript challenges for SEO
React, Vue, Angular, Node, and Polymer. If at least one of these fancy names rings a bell, then most likely you are already dealing with a JavaScript-powered website.
All these JavaScript frameworks provide great flexibility and power to modern websites.
They open a large range of possibilities in terms of client-side rendering (like allowing the page to be rendered by the browser instead of the server), page load capabilities, dynamic-content, user-interaction, and extended functionalities.
If we only look at what has an impact on SEO, JavaScript frameworks can do the following for a website:
- Load content dynamically based on users’ interactions
- Externalize the loading of visible content (see client-side rendering below)
- Externalize the loading of meta-content or code (for example, structured data)
Unfortunately, if implemented without using a pair of SEO lenses, JavaScript frameworks can pose serious challenges to the page performance, ranging from speed deficiencies to render-blocking issues, or even hindering crawlability of content and links.
There are many aspects that SEOs must look after when auditing a JavaScript-powered web page, which can be summarized as follows:
- Is the content visible to Googlebot? Remember the bot doesn’t interact with the page (images, tabs, and more).
- Are links crawlable, hence followed? Always use the anchor () and the reference (href=), even in conjunction with the “onclick” events.
- Is the rendering fast enough?
- How does it affect crawl efficiency and crawl budget?
A lot of questions to answer. So where should an SEO start?
2. Client-side and server-side rendering: The best “frenemies”
Let’s look at how Googlebot crawls and indexes pages, putting it as a very basic sequential process:

- Client-side: all the job is basically “outsourced” to the WRS, which is now in charge of loading all the script and necessary libraries to render that content. The advantage for the server is that when a real user requests the page, it saves a lot of resources, as the execution of the scripts happens on the browser side.
- Server-side: everything is pre-cooked (aka rendered) by the server, and the final result is sent to the bot, ready for crawling and indexing. The disadvantage here is that all the job is carried out internally by the server, and not externalized to the client, which can lead to additional delays in the rendering of further requests.
4. Caffeine (Google’s indexer) indexes the content found
New links are discovered within the content for further crawling
This is the theory, but in the real world, Google doesn’t have infinite resources and has to do some prioritization in the crawling.
3. How Google actually crawls websites
Google is a very smart search engine with very smart crawlers.
However, it usually adopts a reactive approach when it comes to new technologies applied to web development. This means that it is Google and its bots that need to adapt to the new frameworks as they become more and more popular (which is the case with JavaScript).
For this reason, the way Google crawls JS-powered websites is still far from perfect, with blind spots that SEOs and software engineers need to mitigate somehow.
This is in a nutshell how Google actually crawls these sites:
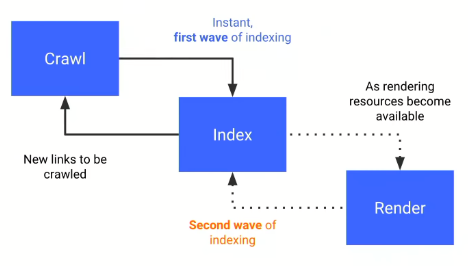
The above graph was shared by Tom Greenaway in Google IO 2018 conference, and what it basically says is – If you have a site that relies heavily on JavaScript, you’d better load the JS-content very quickly, otherwise we will not be able to render it (hence index it) during the first wave, and it will be postponed to a second wave, which no one knows when may occur.
Therefore, your client-side rendered content based on JavaScript will probably be rendered by the bots in the second wave, because during the first wave they will load your server-side content, which should be fast enough. But they don’t want to spend too many resources and take on too many tasks.
In Tom Greenaway’s words:
“The rendering of JavaScript powered websites in Google Search is deferred until Googlebot has resources available to process that content.”
Implications for SEO are huge, your content may not be discovered until one, two or even five weeks later, and in the meantime, only your content-less page would be assessed and ranked by the algorithm.
What an SEO should be most worried about at this point is this simple equation:
No content is found = Content is (probably) hardly indexable
And how would a content-less page rank? Easy to guess for any SEO.
So far so good. The next step is learning if the content is rendered client-side or server-side (without asking software engineers).
4. How to detect client-side rendered content
Option one: The Document Object Model (DOM)
There are several ways to know it, and for this, we need to introduce the concept of DOM.
The Document Object Model defines the structure of an HTML (or an XML) document, and how such documents can be accessed and manipulated.
In SEO and software engineering we usually refer to the DOM as the final HTML document rendered by the browser, as opposed to the original static HTML document that lives in the server.
You can think of the HTML as the trunk of a tree. You can add branches, leaves, flowers, and fruits to it (that is the DOM).
What JavaScript does is manipulate the HTML and create an enriched DOM that adds up functionalities and content.
In practice, you can check the static HTML by pressing “Ctrl+U” on any page you are looking at, and the DOM by “Inspecting” the page once it’s fully loaded.
Most of the times, for modern websites, you will see that the two documents are quite different.
Option two: JS-free Chrome profile
Create a new profile in Chrome and disallow JavaScript through the content settings (access them directly here – Chrome://settings/content).
Any URL you browse with this profile will not load any JS content. Therefore, any blank spot in your page identifies a piece of content that is served client-side.
Option three: Fetch as Google in Google Search Console
Provided that your website is registered in Google Search Console (I can’t think of any good reason why it wouldn’t be), use the “Fetch as Google” tool in the old version of the console. This will return a rendering of how Googlebot sees the page and a rendering of how a normal user sees it. Many differences there?
Option four: Run Chrome version 41 in headless mode (Chromium)
Google officially stated in early 2018 that they use an older version of Chrome (specifically version 41, which anyone can download from here) in headless mode to render websites. The main implication is that a page that doesn’t render well in that version of Chrome can be subject to some crawling-oriented problems.
Option five: Crawl the page on Screaming Frog using Googlebot
And with the JavaScript rendering option disabled. Check if the content and meta-content are rendered correctly by the bot.
After all these checks, still, ask your software engineers because you don’t want to leave any loose ends.
5. The solutions: Hybrid rendering and dynamic rendering
Asking a software engineer to roll back a piece of great development work because it hurts SEO can be a difficult task.
It happens frequently that SEOs are not involved in the development process, and they are called in only when the whole infrastructure is in place.
We SEOs should all work on improving our relationship with software engineers and make them aware of the huge implications that any innovation can have on SEO.
This is how a problem like content-less pages can be avoided from the get-go. The solution resides on two approaches.
Hybrid rendering
Also known as Isomorphic JavaScript, this approach aims to minimize the need for client-side rendering, and it doesn’t differentiate between bots and real users.
Hybrid rendering suggests the following:
- On one hand, all the non-interactive code (including all the JavaScript) is executed server-side in order to render static pages. All the content is visible to both crawlers and users when they access the page.
- On the other hand, only user-interactive resources are then run by the client (the browser). This benefits the page load speed as less client-side rendering is needed.
Dynamic rendering
This approach aims to detect requests placed by a bot vs the ones placed by a user and serves the page accordingly.
- If the request comes from a user: The server delivers the static HTML and makes use of client-side rendering to build the DOM and render the page.
- If the request comes from a bot: The server pre-renders the JavaScript through an internal renderer (such as Puppeteer), and delivers the new static HTML (the DOM, manipulated by the JavaScript) to the bot.
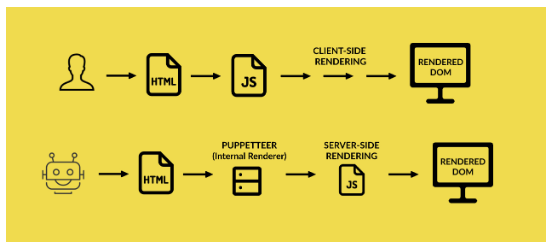
The best of both worlds
Combining the two solutions can also provide great benefit to both users and bots.
- Use hybrid rendering if the request comes from a user
- Use server-side rendering if the request comes from a bot
Conclusion
As the use of JavaScript in modern websites is growing every day, through many light and easy frameworks, it requires software engineers to solely rely on HTML to please search engine bots which are not realistic nor feasible.
However, the SEO issues raised by client-side rendering solutions can be successfully tackled in different ways using hybrid rendering and dynamic rendering.
Knowing the technology available, your website infrastructure, your engineers, and the solutions can guarantee the success of your SEO strategy even in complicated environments such as JavaScript-powered websites.
Giorgio Franco is a Senior Technical SEO Specialist at Vistaprint.
Related reading

Back in September 2018, Google launched its Dataset Search tool, an engine which focuses on delivering results of hard data sources (research, reports, graphs, tables, and the others) in a more efficient manner than the one which is currently offered by Google Search.
Why do “lower authority” sites beat out higher ones for featured snippets? Why are images sometimes from other sites? What kind of content ranks?

According to Google, 53 percent of mobile site visitors leave a page that takes longer than three seconds to load. Five ways to make them stay and convert.

The link building industry is flooded with many myths that’ll never get you results but can get you into a lot of trouble. Nine myths debunked.
This marketing news is not the copyright of Scott.Services – please click here to see the original source of this article. Author: Giorgio Franco
For more SEO, PPC, internet marketing news please check out https://news.scott.services
Why not check out our SEO, PPC marketing services at https://www.scott.services
We’re also on:
https://www.facebook.com/scottdotservices/
https://twitter.com/scottdsmith
https://plus.google.com/112865305341039147737
The post A survival kit for SEO-friendly JavaScript websites appeared first on Scott.Services Online Marketing News.
source https://news.scott.services/a-survival-kit-for-seo-friendly-javascript-websites/
No comments:
Post a Comment